基于(At)自适應四叉樹的(of)網頁分塊技術
2020年10月19日
引言
最近幾年人(people)工智能非常火熱,其中使用(use)的(of)深度學習技術需要(want)收集大(big)量的(of)數據,在(exist)足夠多的(of)數據支撐下才能訓練出(out)完美的(of)模型。圖像處理技術是(yes)深度學習的(of)主要(want)技術之一(one),爲(for)了(Got it)獲取豐富的(of)圖像特征信息,通常需要(want)将圖像灰度化、二值化和(and)角點檢測,等等。圖像分割是(yes)圖像識别和(and)計算機視覺至關重要(want)的(of)預處理,現有的(of)圖像分割方法主要(want)有以(by)下幾類:基于(At)阈值的(of)分割方法、基于(At)區域的(of)分割方法、基于(At)邊緣的(of)分割方法以(by)及基于(At)特定理論的(of)分割方法等。
面向網頁的(of)分塊通常采用(use)基于(At)DOM樹的(of)方法或基于(At)圖像處理的(of)方法,對于(At)基于(At)DOM(DocumentOb⁃jectModel)樹的(of)網頁分塊,兩個(indivual)DOM節點雖然不(No)相同,但呈現的(of)視覺效果可能一(one)樣,而且DOM父子節點之間存在(exist)覆蓋關系,一(one)個(indivual)節點的(of)屬性可能會影響另一(one)個(indivual)節點,導緻網頁分塊誤判。本文采用(use)圖像處理的(of)方法,因爲(for)網頁截圖是(yes)網頁的(of)最終渲染結果,符合人(people)的(of)視覺感知,而基于(At)四叉樹的(of)方法能快速分割圖像,并保持圖像的(of)邊緣細節,能獲得層次化的(of)分塊節點和(and)個(indivual)數,本文提出(out)的(of)自适應的(of)四叉樹是(yes)基于(At)阈值的(of)分塊方法,通過遍曆像素點找到(arrive)精準的(of)分割坐标,使得圖像能被正确地(land)分塊,提高兩個(indivual)圖像差異的(of)識别率。
四叉樹是(yes)一(one)種樹狀的(of)數據結構,常用(use)于(At)二維空間數據的(of)分析與分類,它将數據分成了(Got it)四個(indivual)象限,四叉樹常用(use)于(At)地(land)圖的(of)空間索引、稀疏數據、2D中的(of)快速碰撞檢測。通過四叉樹可以(by)把圖像按一(one)定規則切割成四個(indivual)部分,如圖1、2所示,每一(one)個(indivual)節點下面又可以(by)繼續分成四個(indivual)節點,依次叠代即可得到(arrive)切割後的(of)圖像四叉樹。
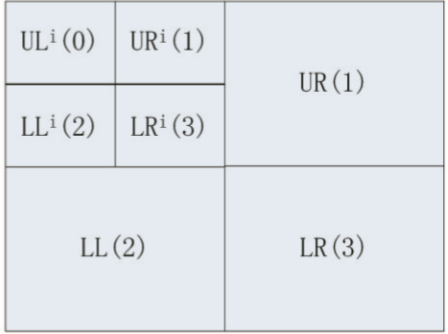
圖1 圖像的(of)四叉樹例子
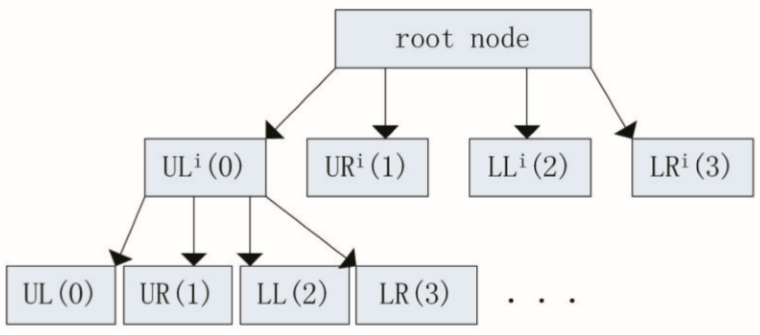
圖2 四叉樹的(of)數據結構圖
此類四叉樹是(yes)均等切分的(of),不(No)适用(use)于(At)網頁分塊,因爲(for)網頁是(yes)由各個(indivual)大(big)小不(No)一(one)的(of)區塊組成,所以(by)本文提出(out)了(Got it)自适應四叉樹,切分後得到(arrive)的(of)四個(indivual)子圖的(of)大(big)小與圖像屬性均方誤差和(and)有關。
對圖像進行分割就需要(want)給出(out)分割的(of)标準,本文分别采用(use)了(Got it)三種分割标準:“GBR顔色均方誤差”、“HSV顔色均方誤差”、“圖片信息熵”。
顔色是(yes)圖像的(of)重要(want)特征,也是(yes)人(people)識别圖像的(of)主要(want)感知特征之一(one),圖像的(of)RGB顔色均方誤差或HSV顔色均方誤差越大(big),圖像的(of)顔色越豐富,圖像就不(No)純,當誤差大(big)于(At)某一(one)個(indivual)阈值時(hour),就認爲(for)圖像是(yes)應該被切割的(of)。對像素顔色特征出(out)現的(of)頻率進行統計可以(by)直觀地(land)表示圖像内容:
RGB顔色均方誤差公式如下:
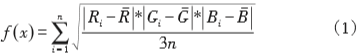
Rˉ、Gˉ、Bˉ是(yes)統計圖像空間中的(of)RGB3個(indivual)分量得到(arrive)的(of)平均值。
HSV顔色均方誤差的(of)公式如下:

HSV模型是(yes)針對用(use)戶觀感的(of)一(one)種顔色模型,側重于(At)色彩表示,Hˉ、Sˉ、Vˉ是(yes)統計HSV模型中的(of)色調(H)、飽和(and)度(S)、明度(V)得到(arrive)的(of)平均值。
信息熵是(yes)對信息的(of)量化度量,信息熵越大(big),不(No)确定性越大(big),那麽對于(At)圖像的(of)信息熵來(Come)說它就越不(No)純,說明圖像應該被切割。計算圖像信息熵均方誤差的(of)公式如下:
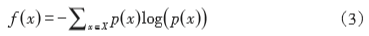
其中x表示像素的(of)RGB中的(of)某一(one)個(indivual)屬性,屬性的(of)取值爲(for)(x1,x2,x3),p(xi)表示屬性值xi出(out)現的(of)頻率,且有∑p(xi)=1,本文取的(of)RGB模型的(of)3個(indivual)分量,采用(use)RGB顔色均方誤差的(of)好處是(yes)計算相似度時(hour)與圖像的(of)旋轉平移和(and)尺寸大(big)小無關。
1自适應四叉樹
四叉樹被認爲(for)是(yes)二叉樹的(of)高維變體,通常的(of)四叉樹是(yes)直接均等切分,而采用(use)自适應的(of)四叉樹需要(want)找到(arrive)最佳切割點,目标是(yes)使得4個(indivual)小分塊的(of)均方誤差和(and)最小。
定義一(one)棵四叉樹:
classQuaternaryNode(object):
def__init__(self,img,box,picmean):
self.img=img
self.box=box#相對于(At)原網頁的(of)四個(indivual)坐标
self.picmean=picmean#圖像某個(indivual)屬性的(of)均值
self.ul=None#左上(superior)節點
self.ur=None#右上(superior)節點
self.ll=None#左上(superior)節點
self.lr=None#右下節點
本文提出(out)的(of)自适應四叉樹算法的(of)實現步驟爲(for):
(1)打開圖像并初始化圖片左上(superior)角坐标爲(for)(0,0)和(and)第一(one)個(indivual)root節點,把圖片轉變成一(one)棵四叉樹;
(2)分别從橫向和(and)縱向遍曆圖片的(of)像素點,計算切割圖像後得到(arrive)的(of)4個(indivual)子圖的(of)最小均方誤差和(and)的(of)切割點。計算像素點與像素平均值的(of)歐氏距離:①計算橫向切割圖像得到(arrive)的(of)2個(indivual)子圖的(of)均方誤差和(and)最小的(of)縱坐标yi;②計算縱向切割圖像得到(arrive)的(of)2個(indivual)子圖的(of)均方誤差和(and)最小的(of)橫坐标xi;
(3)根據切割點的(of)坐标(xi,yi)把一(one)個(indivual)圖像切割成4塊,以(by)坐标爲(for)中點畫兩條線;
(4)把4個(indivual)子圖實例化爲(for)樹的(of)節點,并賦值給父圖;
(5)采用(use)先序遍曆的(of)方式,從左至右遍曆每一(one)個(indivual)節點,判斷切割後的(of)4個(indivual)子圖是(yes)否是(yes)葉子節點,如果已經達到(arrive)最大(big)切割次數或節點的(of)均方誤差小于(At)阈值,則停止切割跳到(arrive)步驟5,否則跳到(arrive)步驟2,繼續叠代切割。
(6)結束切割,得到(arrive)原圖的(of)四叉樹分割圖像。
爲(for)了(Got it)找到(arrive)最佳切割點,如果從頭到(arrive)尾遍曆每一(one)個(indivual)像素點,效率會比較慢,時(hour)間複雜度爲(for)m*n。爲(for)了(Got it)提升效率,隻需要(want)分别遍曆橫坐标和(and)縱坐标,時(hour)間複雜度爲(for)m+n。先橫向遍曆橫坐标,使用(use)一(one)條直線将圖像豎直切割成兩個(indivual)子圖,計算兩個(indivual)子圖的(of)均方誤差和(and),找到(arrive)橫坐标xi,使得均方誤差和(and)最小,然後再縱向遍曆縱坐标得到(arrive)目标yi。
實驗用(use)到(arrive)的(of)圖片的(of)分辨率爲(for)512×512,選用(use)的(of)是(yes)騰訊NBA一(one)個(indivual)網頁的(of)部分截圖,分别使用(use)三種切割标準将圖像切割,選擇Python編程語言實現該算法(Python3.6),主要(want)使用(use)的(of)類庫是(yes)scikit-image,最終得到(arrive)的(of)實驗結果如圖3-5。

圖3 基于(At)GBR顔色均方誤差的(of)切割結果截圖

圖4 基于(At)HSV顔色均方誤差的(of)切割結果截圖

圖5基于(At)圖片信息熵均方誤差的(of)切割結果截圖
将兩個(indivual)網頁截圖分割後得到(arrive)的(of)4個(indivual)小區塊一(one)一(one)對比,計算兩個(indivual)區塊之間的(of)相似度,低于(At)某一(one)阈值時(hour)說明兩個(indivual)區塊有明顯的(of)差異,從而找到(arrive)網頁之間的(of)不(No)兼容性。把一(one)個(indivual)大(big)的(of)問題分割成各個(indivual)小的(of)問題并一(one)一(one)查找,可以(by)提高網頁對比的(of)效率。
使用(use)均值哈希計算兩個(indivual)圖像的(of)相似度(距離越小圖片越相似,距離越大(big)圖片差異性越大(big)),設定阈值,從葉子節點開始遍曆并且隻遍曆葉子節點,逆先序遍曆,兩張圖的(of)相似度計算若大(big)于(At)阈值,則标記兩個(indivual)子圖不(No)相似,然後返回所有不(No)相似的(of)結果并标記于(At)原圖,溯源可以(by)幫助網頁維護人(people)員做兼容性的(of)修複。
2結語
本文給出(out)了(Got it)基于(At)自适應四叉樹的(of)網頁分塊算法,并分别對三種切割标準(RGB、HSV、信息熵的(of)均方誤差)做了(Got it)實驗,觀察實驗結果可以(by)看出(out)該算法可以(by)得到(arrive)滿意的(of)分塊結果,但是(yes)距離整個(indivual)網頁的(of)精确分塊還有一(one)定差距。未來(Come)工作(do),将基于(At)四叉樹的(of)網頁分塊技術應用(use)到(arrive)測試跨浏覽器的(of)網頁兼容性上(superior),應用(use)到(arrive)網絡主題爬蟲的(of)網頁去噪上(superior),可以(by)迅速找到(arrive)網頁中的(of)正文,去除無關簡要(want)的(of)廣告之類的(of)信息,具有一(one)定的(of)實際意義。目前隻能做到(arrive)切割自适應,無法做到(arrive)阈值自适應,因爲(for)不(No)同的(of)圖像顔色有所差異,所以(by)後面的(of)研究是(yes)結合深度學習訓練出(out)模型來(Come)做阈值自适應的(of)四叉樹。
上(superior)一(one)篇:平面設計在(exist)網站建設中的(of)應用(use)研究
下一(one)篇:PHP在(exist)電子商務網站實驗課程中的(of)運用(use)
