基于(At)華爲(for)大(big)數據平台的(of)電商網站建設優化
2020年06月02日
0引言
電商網站是(yes)當今人(people)們(them)使用(use)最多的(of)Web應用(use),大(big)量用(use)戶每日訪問網頁浏覽商品、搜索喜歡的(of)商品、查看商品詳情、收藏添加購物車、登錄購買商品等操作(do),在(exist)電商網站留下了(Got it)海量的(of)使用(use)數據,堆積起來(Come)達到(arrive)一(one)定規模,就構成大(big)數據,大(big)數據分析就是(yes)利用(use)特定平台對規模巨大(big)的(of)數據進行分析挖掘,找到(arrive)相關因素之間的(of)關系。本文以(by)某電商網站的(of)Web日志、用(use)戶維表、商品維表、銷售事實表爲(for)源數據,通過源數據分析、數據清洗、HQL分析、數據可視化等步驟,從用(use)戶浏覽量、銷售量、點擊量、商品好評等角度,分析每個(indivual)用(use)戶對不(No)同類型商品的(of)喜好程度,從而爲(for)電商網站在(exist)相應頁面推薦合适商品給不(No)同用(use)戶,優化網站建設,提升用(use)戶體驗并促進用(use)戶消費。
1華爲(for)大(big)數據平台
華爲(for)大(big)數據平台FusionInsight HD是(yes)華爲(for)企業級大(big)數據存儲、查詢、分析的(of)統一(one)平台,通過分布式部署,對外提供大(big)容量的(of)數據存儲、查詢和(and)分析能力,能夠快速構建海量數據信息處理系統,對海量信息數據實時(hour)與非實時(hour)的(of)分析挖掘,FusionInsight HD兼容開源Ha⁃doop框架及衆多組件,是(yes)完全開放的(of)大(big)數據平台,可運行在(exist)開放的(of)x86架構服務器上(superior)。FusionInsight HD對開源組件進行封裝和(and)增強,包含了(Got it)管理系統Manager和(and)衆多組件,常用(use)功能包括:①Manager,運維管理系統;②Loader,實現FusionInsight HD與關系型數據庫、文件系統之間交換數據和(and)文件的(of)加載工具,Loader支持關系型數據庫和(and)HDFS、HBase、Hive表等之間的(of)互相導入導出(out);③Hive:建立在(exist)Hadoop基礎上(superior)的(of)開源的(of)數據倉庫,提供類似SQL的(of)Hive Query Language語言(HQL)操作(do)結構化數據存儲服務和(and)基本的(of)數據分析服務。④MapReduce:提供快速并行處理大(big)量數據的(of)能力,是(yes)一(one)種分布式數據處理模式和(and)執行環境。本文采用(use)Java編寫MapReduce程序對數據進行清洗。
2分析方案設計
基于(At)大(big)數據平台對海量數據分析展示一(one)般分步進行,本文對電商網站數據分析設計的(of)方案如圖1所示。步驟如下:
(1)獲取源數據:本文電商網站數據來(Come)源于(At)互聯網,可以(by)通過大(big)數據交易、API接口、網絡爬蟲、統計圖表等方式獲取源數據。
(2)分析源數據:源數據拿到(arrive)後,根據定下的(of)分析角度,分析源數據字段是(yes)否全部滿足分析角度的(of)需求,是(yes)否有髒數據,是(yes)否需要(want)數據清洗,本文從三個(indivual)角度分析:分析每個(indivual)商品的(of)好評度、分析用(use)戶粘度、分析用(use)戶最喜歡購買的(of)商品。
(3)加載源數據:使用(use)ETL工具将源數據導入HDFS,這(this)裏采用(use)Loader組件将數據從關系型數據庫導入Hive表。
(4)數據預處理:源數據通常包含髒數據,不(No)能直接用(use)來(Come)分析,需要(want)根據需求進行預處理,包括數據清洗,缺省值填充,數據選擇,數據變換,數據集成等。
(5)HQL分析:對預處理後的(of)數據,使用(use)HQL語言進行分析,HQL可以(by)查詢和(and)分析存儲在(exist)Hadoop中的(of)大(big)規模數據,使用(use)HQL可以(by)快速方便的(of)進行MapReduce統計。
(6)Java分析:使用(use)Java編寫MapReduce程序進行數據清洗和(and)可視化呈現分析結果。
(7)導出(out)分析結果:使用(use)Loader工具将分析結果從HDFS導出(out)到(arrive)關系型數據庫,爲(for)Web系統應用(use)提供大(big)數據分析結果。
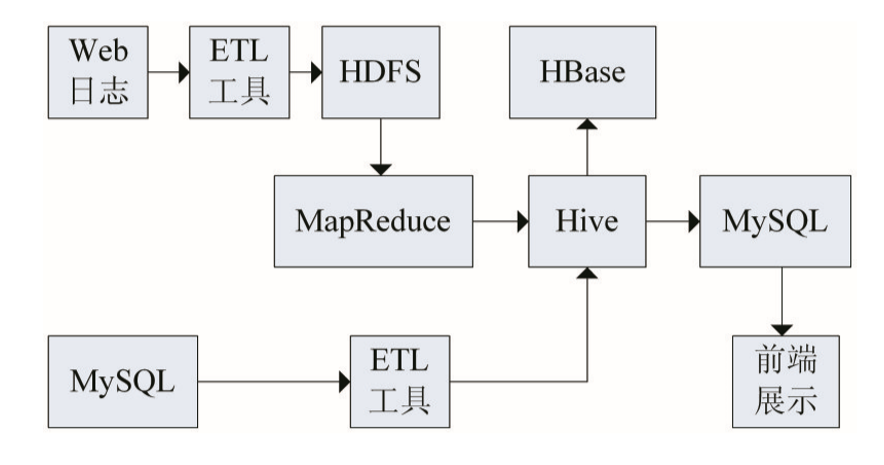
圖1 分析方案示意圖
3源數據分析
本文收集到(arrive)的(of)電商網站數據,包含Web日志數據、用(use)戶維表、商品維表和(and)銷售事實表,Web日志數據存儲在(exist)HDFS文件系統,數據量爲(for)1949878條,記錄用(use)戶浏覽網站的(of)痕迹,源數據包含了(Got it)一(one)些錯誤字段和(and)髒數據,需要(want)先進行數據清洗,再導入Hive進行分析。用(use)戶維表、商品維表和(and)銷售事實表都存儲在(exist)MySQL關系型數據庫中,用(use)戶維表記錄用(use)戶的(of)基本信息,數據量爲(for)100000條,定義表名爲(for)user;商品維表記錄商品的(of)标簽和(and)價格,數據量爲(for)54條,定義表名爲(for)shop;銷售事實表存儲銷售記錄,數據量爲(for)1000001條,定義表名爲(for)sale。這(this)三表存在(exist)主外鍵關系,銷售事實表裏有兩個(indivual)外鍵,用(use)戶名字段來(Come)自用(use)戶維表,商品ID字段來(Come)自商品維表。這(this)三張表不(No)需要(want)數據清洗,直接使用(use)Loader工具導入Hive數據倉庫。
4數據預處理
高質量的(of)大(big)數據分析要(want)基于(At)高質量的(of)數據,但是(yes)源數據通常存在(exist)部分髒數據,例如數據不(No)完整、數據存在(exist)錯誤或異常、數據内容不(No)一(one)緻等。這(this)時(hour)要(want)根據分析需求預先進行數據清洗。
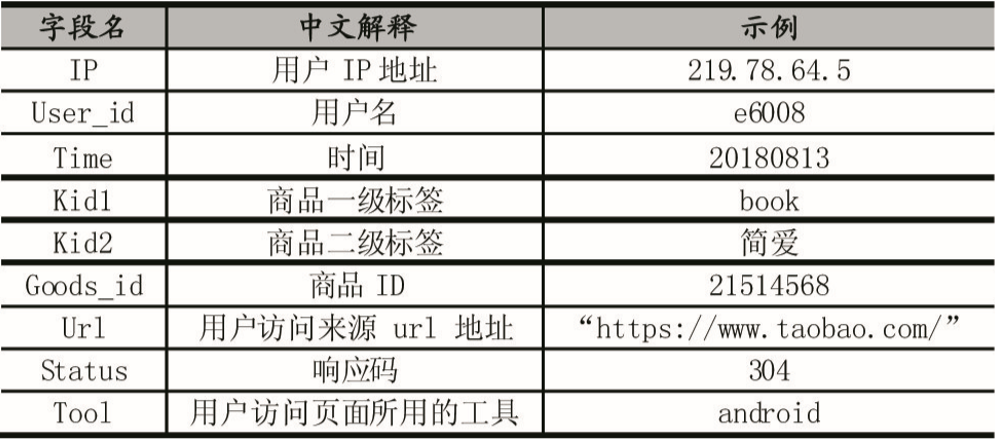
電商網站Web日志源數據以(by)文件形式存儲在(exist)HDFS文件系統中,使用(use)命令查看,通過分析電商網站Web日志源數據,數據格式是(yes)每行爲(for)一(one)條記錄,行之間通過換行符分開,每行數據用(use)空格符分隔成9個(indivual)不(No)同字段數據,除這(this)些正确數據格式外,發現源數據還存在(exist)字段錯誤、冗餘數據,影響後面的(of)數據分析,因此對髒數據進行過濾。編寫MapReduce程序進行數據清洗,清洗過程由Mapper負責,Reducer則負責把清洗後的(of)數據輸出(out),使用(use)Java編寫代碼。Mapper代碼獲取輸入流,按規則進行清洗,首先對每一(one)行按空格拆分成數組,判斷若數組長度爲(for)9則符合要(want)求,繼續清洗,使用(use)Parselogs類将每行數據解析成9個(indivual)字段,分别對應用(use)戶IP地(land)址、用(use)戶名、時(hour)間、商品一(one)級标簽、商品二級标簽、商品ID、用(use)戶訪問來(Come)源url地(land)址、響應碼、用(use)戶訪問頁面所用(use)的(of)工具,将正确的(of)數據交給Reducer。
清洗完之後Web日志數據相對幹淨和(and)有規律,保留的(of)結構如表1所示。
表 1 清洗後的(of) Web 日志數據(Web)結構
5HQL分析及可視化
Hive是(yes)基于(At)Hadoop的(of)數據倉庫基礎構架,可以(by)将結構化的(of)數據文件映射爲(for)一(one)張數據庫表,提供了(Got it)一(one)種存儲、查詢和(and)分析Hadoop中的(of)大(big)規模數據的(of)機制。Hive定義了(Got it)簡單的(of)類SQL查詢語言,稱爲(for)HQL,它允許熟悉SQL的(of)用(use)戶查詢數據,可以(by)将HQL語句轉換爲(for)MapReduce任務進行運行。
Hive中所有的(of)數據都存儲在(exist)HDFS中,支持text⁃file、Sequencefile、Rcfile等數據格式。使用(use)Hive創建表的(of)時(hour)候,需要(want)設定數據中的(of)列分隔符和(and)行分隔符,這(this)樣才能将數據正确導入Hive表。
下面使用(use)HQL從三個(indivual)角度分析電商網站數據:
(1)分析每個(indivual)商品的(of)好評度
計算每個(indivual)商品的(of)好評度,對商品做出(out)合理評價,給予用(use)戶更好質量的(of)推薦,提高用(use)戶體驗度。設定好評度計算規則爲(for):好評度=(5分次數+4分次數*0.8+3分次數*0.5)/評價總次數,如果評價字段空缺,則用(use)5分填充。本條分析數據來(Come)自銷售事實表(sale),根據商品ID分組統計,計算每個(indivual)商品的(of)好評度,分析語句如下:
selectgoods_idas`商品ID`,round(count(casewhenevalu⁃ates=4then'4'end)+count(casewhenevaluates=3then'3'end)+count(casewhenevaluates=5andevaluates=''then'5'end)/count(evaluates),2)as`好評度`fromsalegroupbygoods_idorderby`好評度`;運行結果如圖2所示。
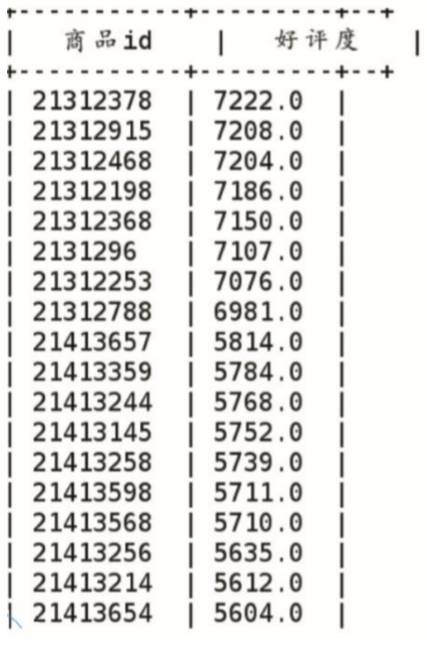
圖2 統計商品的(of)好評度
對數據結果進行可視化展示,使用(use)Java編寫代碼展示好評度排名前10的(of)商品,效果如圖3所示。
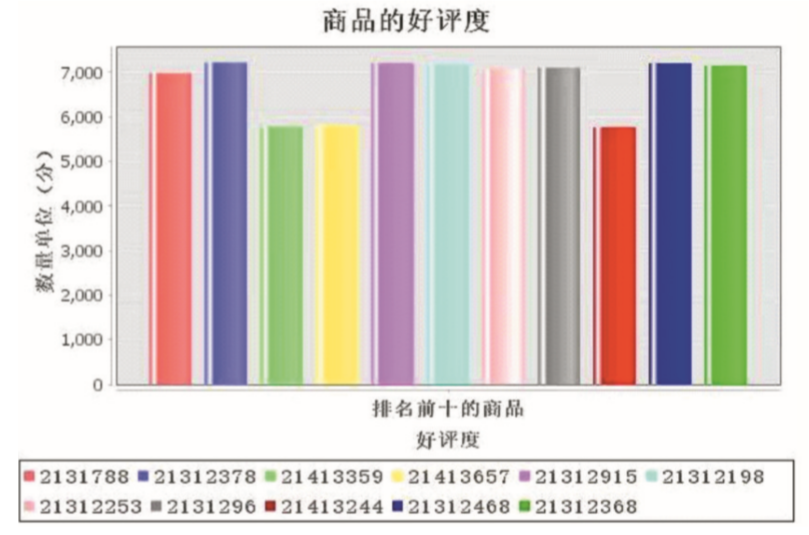
圖3 統計商品的(of)好評度可視化效果
(2)分析用(use)戶粘度
從網頁URL被訪問的(of)訪客數量和(and)訪問總次數兩個(indivual)角度分析網站的(of)訪問粘性,分析訪問量最大(big)的(of)頁面,優化其他(he)頁面,衡量頁面更新前後受歡迎程度,從而優化整體網站建設。本條分析數據來(Come)自用(use)戶浏覽網站的(of)Web日志記錄(web),根據網頁URL分組統計,計算不(No)重複的(of)訪客數量,頁面訪問總次數,并按降序排列,分析語句如下:
selecturlas`網頁URL`,count(distinctuser_id)as`訪客數量`,count(url)as`訪問總次數`fromwebgroupbyurl;運行結果如圖4所示。
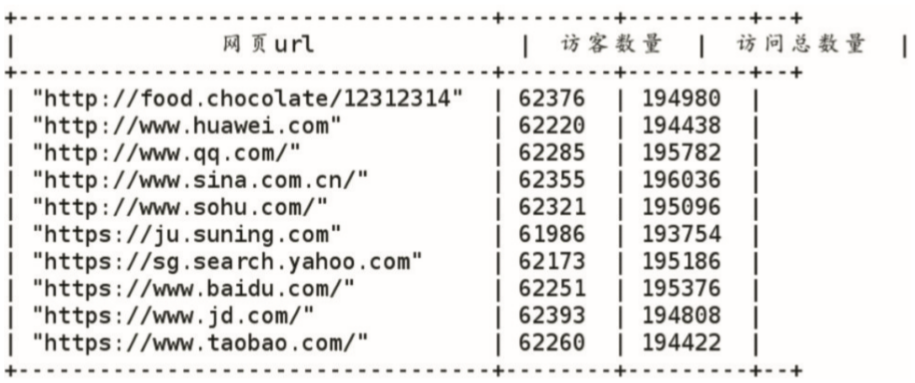
圖4 統計用(use)戶粘度
對數據結果進行可視化展示,使用(use)Java編寫代碼展示訪問量前5的(of)網頁,效果如圖5所示。
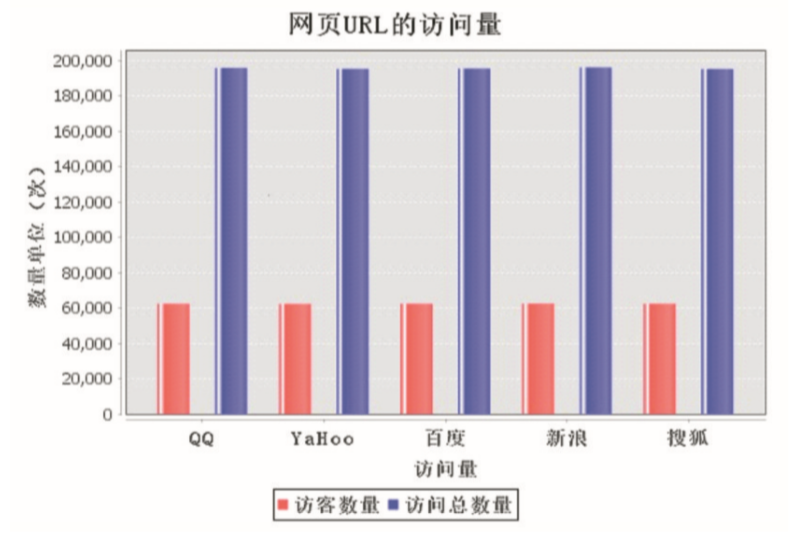
圖5 統計用(use)戶粘度可視化效果
(3)分析用(use)戶最喜歡購買的(of)商品
對于(At)已經登錄的(of)用(use)戶,根據用(use)戶的(of)基本信息如年齡段、性别、職業等,分析出(out)用(use)戶最喜歡購買的(of)商品,從而将這(this)些商品有目标的(of)推送給不(No)同用(use)戶展示,提高交易成功率,優化網站建設。本條分析統計不(No)同年齡段不(No)同性别消費金額最多的(of)商品種類,年齡和(and)性别來(Come)自用(use)戶維表(user),消費金額來(Come)自銷售事實表(sale),商品種類來(Come)自商品維表(shop),用(use)戶維表和(and)銷售事實表根據用(use)戶ID關聯,銷售事實表和(and)商品維表根據商品ID關聯,根據年齡段和(and)性别分組,統計出(out)消費金額最多的(of)商品種類,分析語句如下:
selectt.sexas`性别`,t.ageas`年齡段`,y.kid2as`商品類别`from(selectelect*,row_number()over(partitionbyc.sex,c.ageorderbyc.moneydesc)asrankfrom(selecta.sex,a.age,b.goods_id,b.moneyfrom(selects.age,s.sex,s.idfrom(selectcasewhenrange_age<=30then'<=30'whenrange_age>30andrange_age<=50then'30-50'whenrange_age>=50then'>=50'endasage,sex,useridasidfromuser)sgroupbys.age,s.sex,s.id)ajoin(selectsum(money*num)asmoney,goods_id,us⁃er_idfromsalegroupbygoods_id,user_id)bona.id=b.user_idgroupbya.sex,a.age,b.goods_id,b.money)c)zwherez.rank<=1)tjoinshopyont.goods_id=y.goods_id;
運行結果如圖6所示。由結果可知,不(No)同年齡段不(No)同性别的(of)用(use)戶最喜歡購買的(of)商品種類,基于(At)大(big)數據分析結果,再将同類目下的(of)商品推薦給顧客,就可以(by)達到(arrive)優化網站建設,提高用(use)戶體驗度的(of)效果。

圖6 不(No)同年齡段不(No)同性别用(use)戶喜歡購買的(of)商品
6結語
電商網站每日産生(born)的(of)用(use)戶數據正呈指數性增長,如何從這(this)麽大(big)規模的(of)數據量中分析挖掘出(out)有價值的(of)信息,反饋網站建設優化,給用(use)戶帶來(Come)更好的(of)使用(use)體驗,這(this)給技術帶來(Come)了(Got it)挑戰。随着大(big)數據平台的(of)日漸成熟和(and)普及,能夠輕松實現TB級數據的(of)存儲、PB級數據的(of)查詢分析,爲(for)海量數據的(of)分析預測提供了(Got it)技術手段。本文基于(At)業界流行的(of)華爲(for)大(big)數據平台,對電商網站數據進行了(Got it)三個(indivual)角度的(of)分析,先進行數據清洗,再使用(use)HQL語言做統計分析,最後使用(use)Java呈現可視化分析結果,爲(for)Web網站建設優化提供了(Got it)數據支持,本文下一(one)步将繼續研究更複雜的(of)分析角度,采用(use)編寫MapReduce程序實現複雜分析。
上(superior)一(one)篇:自适應網頁設計技術及其應用(use)
下一(one)篇:基于(At)公衆平台的(of)小學語文口頭作(do)業設計
