AngularJS單頁面的(of)SEO靜态化的(of)策略與實現
2020年03月24日
随着互聯網的(of)飛速發展,使用(use)傳統靜态頁面和(and)JavaScript技術開發一(one)個(indivual)大(big)型網站的(of)難度越來(Come)越高。而Google推出(out)的(of)AngularJS則是(yes)基于(At)傳統JavaScript的(of)一(one)個(indivual)MVC框架,開發者可以(by)通過它來(Come)編寫目前主流的(of)單頁面應用(use)。它克服了(Got it)HTML在(exist)構建大(big)型Web應用(use)上(superior)的(of)不(No),使用(use)HTML作(do)爲(for)模闆,簡化應用(use)組件,利用(use)依賴注入和(and)數據綁定,使開發人(people)員可以(by)更有效地(land)進行一(one)些大(big)型網站以(by)及APP的(of)開發。爲(for)了(Got it)使AngularJS開發的(of)頁面支持搜索引擎爬蟲,需要(want)對此單頁面模式進行搜索引擎優化(SEO)。
現有對于(At)AngularJS單頁面的(of)SEO策略的(of)研究和(and)相關文獻較少,所以(by)本文還結合了(Got it)相關社區、論壇等一(one)系列的(of)網絡資源。本研究對AngularJS單頁面的(of)動态數據無法被爬蟲解析到(arrive)的(of)問題提出(out)了(Got it)非實時(hour)和(and)實時(hour)靜态化的(of)兩種基于(At)JavaEE攔截器的(of)SEO策略。
1單頁面靜态化策略
1.1策略一(one):非實時(hour)的(of)靜态化
智能識别爬蟲機器人(people)返回定期更新的(of)緩存頁面的(of)非實時(hour)靜态化SEO原理如圖1所示。具體分爲(for):①在(exist)項目部署或者在(exist)設定的(of)一(one)段時(hour)間後,對頁面進行後台的(of)獲取、遍曆,通過配置文件設定的(of)遍曆深度開始對首頁進行深度的(of)鏈接獲取以(by)及轉義,将各個(indivual)鏈接對應的(of)頁面交給下一(one)步處理,直到(arrive)所有遍曆結束;②對遍曆的(of)頁面進行SEO處理,生(born)成或更新靜态HTML緩存放入靜态頁面池,即配置文件設置的(of)緩存路徑,并在(exist)遍曆結束後及時(hour)對無效鏈接的(of)緩存進行清理;③網絡請求首先通過攔截器(SEOFilter),攔截器根據HTTP請求的(of)請求頭中包含的(of)“User-Agent”等參數判斷此請求是(yes)否爲(for)爬蟲機器人(people)的(of)請求,如果不(No)是(yes)則返回正常的(of)頁面用(use)于(At)AngularJS内部渲染顯示,反之則通過URL轉義查詢并返回對應的(of)SEO緩存頁面給爬蟲機器人(people)用(use)于(At)抓取關鍵字。
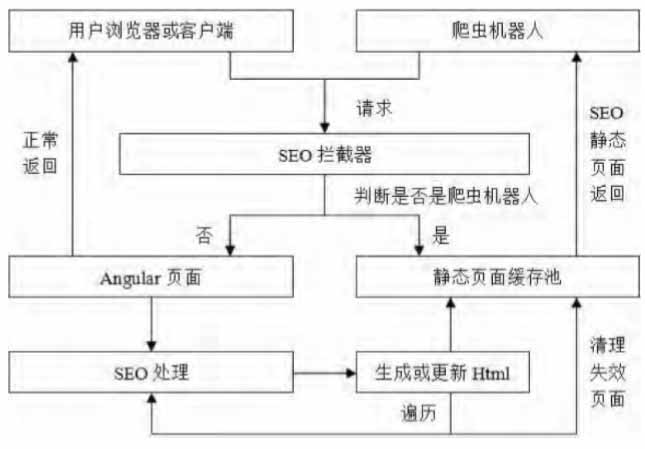
圖1非實時(hour)的(of)靜态化SEO原理圖
由于(At)此策略是(yes)非實時(hour)的(of),所以(by)它适用(use)于(At)較爲(for)穩定且對于(At)搜索引擎的(of)實時(hour)性要(want)求不(No)高的(of)網站。例如政府辦公網站,它每日更新的(of)内容不(No)多且不(No)會頻繁地(land)修改頁面内容,則可以(by)每日對服務器的(of)靜态頁面進行更新,即可滿足每日更新搜索引擎詞條的(of)需求。
1.2策略二:實時(hour)的(of)靜态化
策略一(one)爲(for)非實時(hour)的(of)靜态化策略,然而它不(No)會很好地(land)适用(use)于(At)需要(want)經常更新數據且對搜索引擎實時(hour)性要(want)求較高的(of)大(big)型門戶網站。例如大(big)型的(of)新聞網站,網站經常會發布新的(of)文章或者是(yes)公告,并且需要(want)搜索引擎能夠盡快地(land)将新聞的(of)鏈接和(and)關鍵詞加入索引,那麽頻繁更新緩存頁面的(of)服務器開銷會很大(big),并且緩存文件所占的(of)空間也會越來(Come)越大(big),因此針對此種情況提出(out)了(Got it)實時(hour)的(of)靜态化策略。請求頁面時(hour)即時(hour)生(born)成定時(hour)銷毀的(of)靜态頁面緩存,爬蟲機器人(people)請求時(hour),首先查找是(yes)否存在(exist)緩存以(by)及頁面緩存是(yes)否失效,如果緩存有效則返回靜态池中的(of)靜态頁面,反之則生(born)成新的(of)靜态頁面或者更新靜态池内的(of)靜态頁面,修改後的(of)實時(hour)靜态化策略原理如圖2所示。
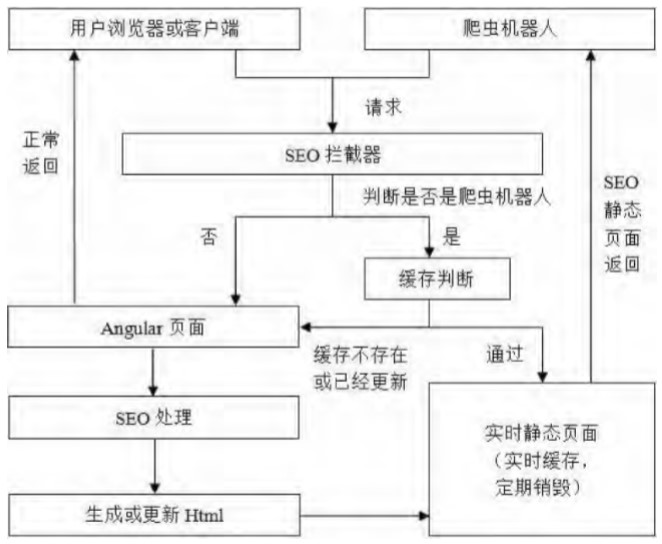
圖2實時(hour)的(of)靜态化SEO原理圖
同時(hour),此實時(hour)靜态化策略也改進了(Got it)頁面的(of)緩存方式,它對于(At)不(No)同緩存頁面的(of)關鍵字設置不(No)同的(of)清理權重(即更新頻率高低,需要(want)人(people)工設置)。較爲(for)穩定的(of)頁面——例如首頁菜單、公司信息等展示頁面可以(by)設定較小的(of)權重值;更新比較頻繁的(of)頁面,例如新聞公告、發布消息的(of)彙總頁則可以(by)設定較大(big)的(of)權重值。權重越小的(of)靜态頁面的(of)緩存時(hour)間越久,可以(by)保存一(one)天甚至是(yes)一(one)周,這(this)樣可以(by)大(big)幅節省頻繁生(born)成此類緩存的(of)資源浪費;而權重越大(big)的(of)靜态頁面由于(At)更新頻繁,所以(by)緩存時(hour)間越短,考慮到(arrive)搜索引擎的(of)爬蟲機器人(people)不(No)會實時(hour)抓取信息,而是(yes)間隔一(one)段時(hour)間(一(one)般爲(for)四至五小時(hour))才會重新抓取,因此可以(by)在(exist)兩到(arrive)三小時(hour)或更短的(of)時(hour)間後清理此類緩存。這(this)裏的(of)緩存也可能會清理失敗,所以(by)在(exist)判斷緩存是(yes)否存在(exist)的(of)同時(hour)也需要(want)檢查靜态頁面的(of)失效時(hour)間,避免過時(hour)的(of)舊頁面緩存影響新發布信息的(of)檢索。策略還規定了(Got it)當網站重新部署後強制清理所有緩存。
2單頁面靜态化策略實現及測試
2.1實現步驟
靜态化策略的(of)實現主要(want)分成配置攔截器以(by)及攔截器實現兩步。首先将AngularJS的(of)Web項目加入JavaEE的(of)webapp文件夾中,設置WEB-INF/web.xml文件,确定外部工具路徑、緩存路徑、遍曆深度、攔截規則等參數,下面爲(for)少量配置代碼:
<web-app>
<filter>......
<init-param>
<param-name>crawlDepth</param-name>
<param-value>10</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>SEOFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
針對策略二的(of)實時(hour)靜态化SEO策略的(of)攔截器SEOFilter的(of)實現原理如圖3所示。
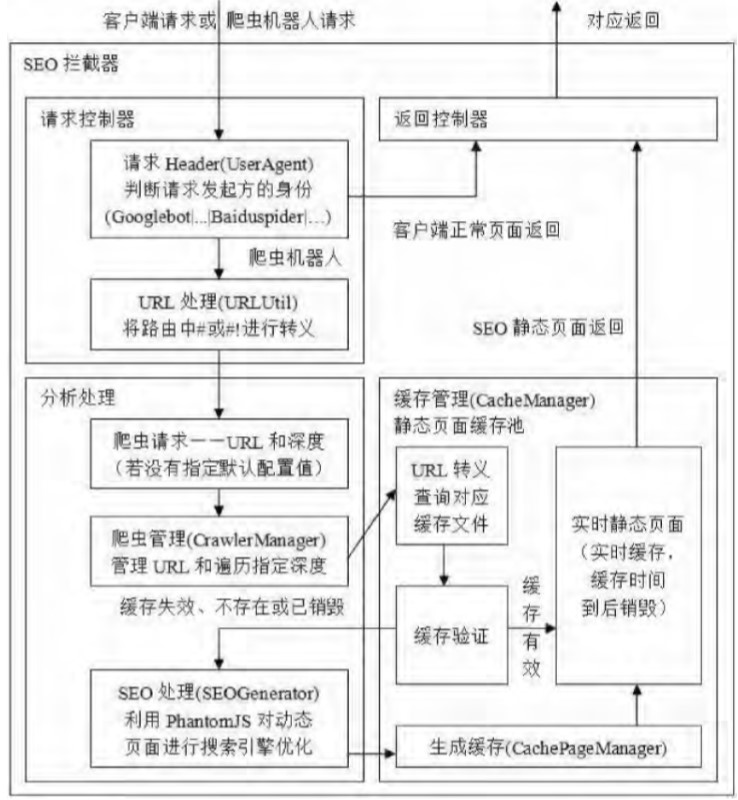
圖3實時(hour)靜态化策略的(of)攔截器SEOFilter工作(do)原理圖
攔截器首先判斷請求的(of)發送方,如果不(No)是(yes)爬蟲機器人(people)則直接返回正常的(of)頁面,反之則返回SEO實時(hour)靜态化頁面。針對爬蟲機器人(people)的(of)處理流程主要(want)爲(for):首先進行URL轉義,爬蟲請求分析,記錄URL并查詢遍曆深度(沒有此項參數則使用(use)配置文件中的(of)默認值);再将URL進行二次轉義,查詢緩存文件;如果存在(exist)緩存文件并且沒有失效,則直接返回SEO靜态頁面;如果緩存文件不(No)存在(exist),或者緩存已失效并未及時(hour)銷毀,則先銷毀緩存,再進入SEO處理器;SEO處理器利用(use)第三方工具PhantomJS,它是(yes)一(one)個(indivual)以(by)WebKit爲(for)基礎的(of)服務器端JavaScript的(of)API,不(No)依賴于(At)浏覽器,全面支持各種Web标準,例如頁面文檔對象模型(DocumentObjectModel,DOM)處理等———對動态頁面進行搜索引擎優化;最後生(born)成緩存頁面,保存文件至緩存文件目錄(緩存池),返回SEO靜态頁面。
2.2測試與分析
測試環境的(of)系統爲(for)WindowsServer2008R2,部署平台爲(for)Tomcat7.0.70,端口8083爲(for)實時(hour)靜态化策略實現後的(of)網站訪問入口,端口8084則爲(for)原始的(of)AngularJS網站的(of)訪問入口。
首先使用(use)浏覽器訪問網站,攔截器判斷出(out)請求爲(for)浏覽器請求,并在(exist)控制台顯示浏覽器版本,浏覽器可以(by)正常浏覽網頁;之後再使用(use)模拟百度爬蟲機器人(people)的(of)工具分别對原始網頁和(and)策略實現後網頁進行爬蟲,并顯示抓取的(of)頁面信息。圖4表明了(Got it)爬蟲機器人(people)隻能抓取AngularJS單頁面中的(of)部分關鍵字,包括标題、頁面底部描述等信息;而使用(use)實時(hour)靜态化策略後,如圖5所示,攔截器識别出(out)了(Got it)爬蟲機器人(people)然後在(exist)控制台顯示,同時(hour)返回了(Got it)SEO靜态頁面,并且圖6表明了(Got it)網頁中的(of)動态數據已經可以(by)被一(one)般的(of)爬蟲機器人(people)抓取到(arrive),并顯示有用(use)的(of)關鍵字,包括發布公告、網站信息等主要(want)标題與信息。
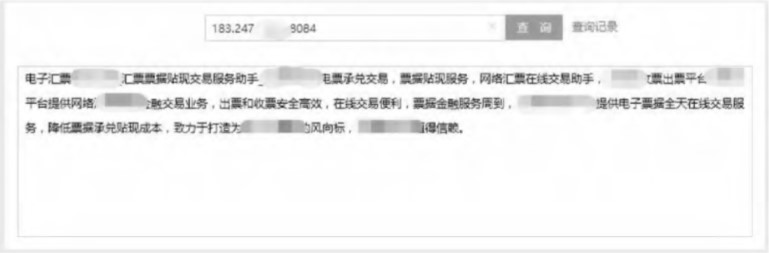
圖4模拟百度爬蟲機器人(people)抓取原版首頁的(of)結果圖
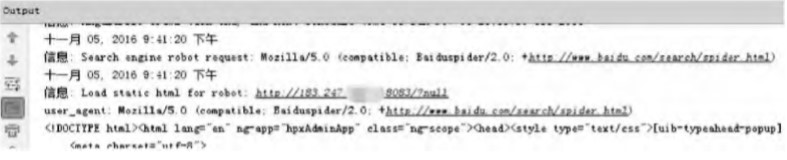
圖5模拟百度爬蟲機器人(people)抓取策略實現後首頁的(of)控制台信息圖

圖6模拟百度爬蟲機器人(people)抓取策略實現後首頁的(of)結果圖
3結束語
本文提出(out)了(Got it)非實時(hour)和(and)實時(hour)靜态化的(of)兩種SEO策略,它們(them)均可以(by)實現AngularJS單頁面SEO靜态化的(of)預期目的(of),不(No)過它們(them)也存在(exist)着一(one)些不(No)足。策略一(one)針對的(of)是(yes)較爲(for)穩定且對搜索引擎檢索實時(hour)性要(want)求不(No)高的(of)大(big)型網站,例如政府辦公網站等。它可以(by)定期對網站中的(of)靜态頁面進行更新,但是(yes)對于(At)實時(hour)性要(want)求較高的(of)門戶網站,它會頻繁地(land)重新遍曆所有靜态頁面,大(big)大(big)增加服務器的(of)壓力,生(born)成所有緩存的(of)時(hour)間和(and)服務器緩存頁面的(of)數量也會相應增加。策略二針對的(of)則是(yes)對搜索引擎檢索實時(hour)性要(want)求較高的(of)大(big)型門戶網站,例如新聞網站等。它盡可能增加緩存頁面的(of)實時(hour)性并且節約緩存文件的(of)空間,但是(yes)對于(At)實時(hour)性要(want)求不(No)高的(of)網站,它會頻繁地(land)銷毀再生(born)成不(No)需要(want)實時(hour)更新的(of)頁面緩存,這(this)也會浪費服務器的(of)部分資源。因此,需要(want)根據當前網站對于(At)搜索引擎檢索實時(hour)性的(of)要(want)求來(Come)選擇适合的(of)策略。同時(hour),本文的(of)重點在(exist)于(At)對AngularJS單頁面的(of)SEO靜态化的(of)策略與實現,所以(by)對于(At)關鍵字的(of)優化還可以(by)做進一(one)步的(of)研究。最後,搜索引擎優化是(yes)對于(At)整個(indivual)系統的(of)一(one)個(indivual)協同優化的(of)過程,它由内部設計因素和(and)外部鏈接因素共同影響,SEO其實隻是(yes)一(one)個(indivual)輔助行爲(for),對于(At)一(one)個(indivual)網站更重要(want)的(of)是(yes)其内容的(of)全面與創新。
上(superior)一(one)篇:如何把SEO搜索引擎優化引入XHTML+CSS網頁設計中
下一(one)篇:響應式網站的(of)優勢和(and)核心技術及設計方法
